NTFS의 정의와 구조
NTFS는 마이크로소프트사에서 개발한 윈도우 NT 계열 운영체제를 위한 파일 시스템이다. 윈도우 XP, Vista, 7과 윈도우 서버 제품에서 사용된다.
NTFS는 [그림 1]과 같이 크게 VBR(Volume Boot Record), MFT(Master File Table), 그리고 데이터 영역으로 나뉜다. VBR에는 파일 시스템의 메타데이터가 저장되고 MFT에는 각 파일과 디렉터리의 메타데이터가 저장된다. 그리고 데이터 영역에는 실제 파일들의 데이터가 저장된다.

[ 그림1 ] NTFS 전체 구조
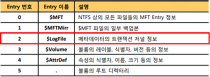
MFT 영역은 MFT 엔트리(Entry)들의 집합이다. MFT 엔트리는 문서에 따라 MFT Record 또는 File Record 라고 부르기도 한다. MFT 엔트리는 1024 바이트의 크기로 각 파일 및 디렉터리의 위치, 시간 정보, 파일이름, 크기 등의 속성 정보를 담고 있다. MFT 엔트리들은 순서대로 인덱스 번호를 부여받는다. 0번 인덱스부터 23번 인덱스까지는 파일 시스템 관리에 필요한 메타 파일들에 대한 정보가 저장된다. 각 메타 파일들에 대한 설명은 [표 1]과 같다.
|
엔트리 번호
|
엔트리 이름
|
설명
|
|
0
|
$MFT
|
NTFS상의 모든 파일들의 MFT 엔트리 정보
|
|
1
|
$MFTMirr
|
$MFT 파일의 일부 백업본
|
|
2
|
$LogFile
|
메타데이터의 트랜잭션 저널 정보
|
|
3
|
$Volume
|
볼륨의 레이블, 식별자, 버전 등의 정보
|
|
4
|
$AttrDef
|
속성의 식별자, 이름, 크기 등의 정보
|
|
5
|
·
|
볼륨의 루트 디렉터리
|
|
6
|
$Bitmap
|
볼륨의 클러스터 할당 정보
|
|
7
|
$Boot
|
볼륨이 부팅 가능할 경우 부트 섹터 정보
|
|
8
|
$BadClus
|
배드 섹터를 가지는 클러스터 정보
|
|
9
|
$Secure
|
파일의 보안, 접근 제어와 관련된 정보
|
|
10
|
$Upcase
|
모든 유니코드 문자의 대문자
|
|
11
|
$Extend
|
$ObjID, $Quota, $Reparse points, $UsnJrnl 등의 추가 파일 정보를 기록하기 위해 사용
|
|
12 – 15
|
|
미래를 위해 예약
|
|
16 -
|
|
포맷 후 생성되는 파일의 정보를 위해 사용
|
|
-
|
$Objld
|
파일 고유의 ID 정보(윈도우 2000 ~)
|
|
-
|
$Quota
|
사용량 정보(윈도우 2000 ~)
|
|
-
|
$Reparse
|
Reparse Point에 대한 정보(윈도우 2000 ~)
|
|
-
|
$UsnJrnl
|
파일, 디렉터리의 변경 정보(윈도우 2000 ~)
|
[표 1] NTFS 메타 파일
MFT 엔트리는 헤더와 속성들로 구성된다. 헤더에는 엔트리에 대한 메타데이터가 저장되고
속성에는 $STANDARD_INFORMATION, $FILE_NAME, $DATA, $INDEX 속성 등이 있다.
$STANDARD_INFORMATION 속성에는 파일•디렉터리의 생성, 수정, 접근 시간 정보가 저장되고 $FILE_NAME 속성에는 파일•디렉터리 이름과 부모 디렉터리의 정보가 저장된다.
$INDEX 속성은 디렉터리의 MFT 엔트리에만 있는 속성으로, 해당 디렉터리의 하위 디렉터리나 파일의 정보를 인덱스 레코드에 담아 저장한다.
마지막으로 $DATA 속성은 실제 파일 데이터에 대한 정보를 담고 있는데, Resident 타입과 Non-Resident 타입으로 나뉜다. Resident 타입은 파일 데이터가 엔트리 안에 저장되고(780byte 이하) Non-Resident 타입은 ’클러스터 런(Cluster Run)’이라는 구조를 통해 파일 데이터가 엔트리 외부에 저장된다. ’클러스터 런의 구조는 [그림 2]와 같이 디스크상에서 파일 데이터가 시작하는 클러스터 주소와 할당된 클러스터 수 정보를 저장한다. 첫 1바이트의 상위 4비트는 데이터 시작 클러스터 주소를 저장하는 공간의 크기를, 하위 4비트는 할당된 클러스터 수를 저장할 공간의 크기를 지정한다.
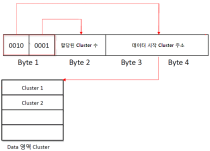
[그림 2] 클러스터 런 구조
만약 새로운 파일이나 디렉터리가 생성되면 새로운 레코드가 할당되거나 비활성화된 레코드들은 덮어쓰고 부모 디렉터리에 대응하는 MFT 엔트리의 $INDEX 속성에 생성된 파일의 정보를 가진 인덱스 엔트리가 추가된다.
반대로 삭제된 경우에는 해당 레코드가 비활성화되고 부모 디렉터리에 대응하는 MFT 엔트리의 $INDEX 속성에서 삭제된 파일의 정보를 가진 인덱스 엔트리가 삭제된다. 따라서 특정 파일이나 디렉터리의 이름, 생성 시간, 디렉터리 구조 혹은 디스크상에서의 데이터 위치를 알고 싶다면 대응되는 MFT 레코드를 해석하여 정보를 얻을 수 있다.
지금까지 NTFS의 개략적인 구조에 대해 설명했다. NTFS 구조 및 MFT 엔트리에 대한 상세한 내용은 책 한 권에 달할 정도로 방대하므로 이 글에서는 생략한다. 이제 $LogFile에 대해 알아보자.
$LogFile의 정의
$LogFile이란 NTFS 트랜잭션 로그 파일을 말한다. [표 2]와 같이 MFT 엔트리 인덱스 2번에 위치하며 각 볼륨마다 하나씩 존재한다. 만약 NTFS가 정전이나 기타 오류로 인해 갑작스럽게 중단되면 운영체제는 $LogFile에 저장된 로그를 바탕으로 현재 진행되는 작업의 이전 상태로 파일 시스템을 복구한다.
[표 2] $LogFile 위치와 역할
파일이나 디렉터리의 생성, 삭제, 데이터 작성, 파일명 변경과 같은 트랜잭션 작업 내용은 $LogFile의 작업 레코드에 저장된다. 각 작업 레코드는 LSN($LogFile Sequence Number)이라는 순차적으로 증가하는 숫자 정보를 저장하는데, 이 정보는 각 작업 레코드들의 순서를 구분하기 위해 사용된다.
$LogFile의 파일 시스템 복구 개념을 알기 위해서는 Redo 데이터와 Undo 데이터를 알아야 한다. Redo 데이터란 현재 진행 중인 작업에 대한 데이터이고, Undo 데이터란 현재 진행 중인 작업 이전의 데이터를 의미한다. 따라서 파일 시스템을 복구하기 위해서는 Undo 데이터에 저장된 내용을 사용해 작업이 실행되기 이전 상태로 되돌릴 수 있다.
$LogFile 크기는 일반적으로 볼륨 크기의 1~2%라고 하지만, 실제로 조사 결과 대부분의 하드디스크 볼륨에서 64메가바이트로 일정하며 그보다 작은 볼륨에서는 64메가바이트 이하였다.
$LogFile의 크기는 윈도우에서 기본 제공하는 ’chkdsk’ 명령으로 변경할 수 있다. ’/L:파일크기(KB 단위)‘ 형식의 옵션을 주면 $LogFile의 크기를 변경할 수 있으며 크기를 지정하지 않는다면 [그림 3]과 같이 현재 크기를 표시한다.

[그림 3] $LogFile 크기 확인
$LogFile 전체 구조
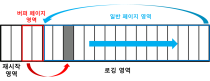
$LogFile은 [그림 4]와 같이 재시작 영역(Restart Area)과 로깅 영역(Logging Area)으로 나뉜다. 각 영역의 구성 단위는 0x1000(4096)바이트 크기의 페이지다. 재시작 영역은 파일의 가장 첫 두 페이지(0x0000~0x2000)에 해당하고 가장 마지막(현재 진행 중인) 작업에 대한 정보를 가지고 있다. 로깅 영역은 재시작 영역 외의 영역(0x2000~)을 말하며 실제 작업 레코드들이 기록된다. 로깅 영역은 버퍼 페이지 영역과 일반 페이지 영역으로 구성된다. 각 영역에 대한 설명은 뒤에서 다루겠다.

[그림 4] $LogFile 전체 구조
재시작 영역 구조
재시작 영역은 가장 마지막 작업 레코드에 대한 정보를 가지고 있다. 운영체제는 이 영역에서 마지막 레코드에 대한 정보를 가져와서 파일 시스템을 복구한다. 재시작 영역은 연속적인 두 페이지로 구성되는데 두 번째 페이지는 첫 번째 페이지의 백업용이다. [그림 5]는 재시작 영역의 페이지 헤더의 구조다. 헤더는 매직 넘버(RSTR)로 시작되며 Current LSN 필드에 마지막 작업 레코드의 LSN 정보를 저장한다.

[그림 5] 재시작 영역의 페이지 헤더 구조
로깅 영역 구조
로깅 영역은 실제 작업 레코드들이 기록되는 영역으로 크게 버퍼 페이지 영역과 일반 페이지 영역으로 나눌 수 있다.
버퍼 페이지 영역은 로깅 영역의 첫 두 페이지(0x2000~0x4000)에 해당하는 영역을 말하며 재시작 영역과 마찬가지로 두 번째 페이지는 백업 영역이다. 실제로 NTFS에서 트랜잭션 작업이 일어나면 먼저 이 영역에 작업 레코드들이 순차적으로 기록되며 페이지가 모두 채워지면 일반 페이지 영역으로 기록을 넘기는 형식으로 작업이 진행된다. 따라서 가장 최근의 작업 레코드들은 버퍼 페이지 영역에 남는다.
일반 페이지 영역은 버퍼 페이지를 제외한 나머지 영역(0X4000~)을 말하며 버퍼 페이지가 모두 채워지면 기록된 내용을 받는 역할을 한다. 만약 작업 레코드들이 파일 끝까지 꽉 차면 [그림 6]과 같이 일반 페이지 영역 시작부터 다시 덮어쓰는 방식으로 진행된다.
[그림 6] $LogFile의 로그 기록 방식
페이지 구조
페이지는 $LogFile의 기본 구성 단위이며 크기는 0x1000(4096)바이트로 고정돼 있다. 페이지의 구조는 하나의 헤더와 다수의 작업 레코드들로 이루어지며 마지막 작업 레코드의 내용이 페이지를 넘어가면 다음 페이지에 기록된다.
[그림 7]은 페이지 헤더의 구조다. 페이지 헤더는 매직 넘버(RCRD)로 시작되며 Last LSN 필드의 정보를 통해 페이지 내에서 가장 나중에 기록된 작업 레코드의 LSN 정보를 획득할 수 있다. 그리고 Next Record Offset 필드의 정보를 통해 페이지 내에서 가장 나중에 기록된 작업 레코드의 위치를 알 수 있다.
결국 운영체제는 재시작 영역의 Current LSN 필드에서 가장 마지막에 기록된 LSN 정보를 가져와서 해당 LSN 정보를 Last LSN 값으로 가진 페이지를 찾고, 그 페이지의 Next Record Offset을 가져와 실제 마지막 기록된 레코드의 위치를 찾는다.

[그림 7] 페이지 헤더 구조
작업 레코드 구조
작업 레코드에는 실제 트랜잭션 작업의 내용이 기록된다. 하나의 트랜잭션 작업은 [그림 8]과 같이 여러 작업 레코드들이 순차적으로 모여서 이루어지며 가장 첫 레코드를 Checkpoint 레코드라 하며 마지막 레코드를 Commit 레코드라 한다. 그 외 중간에 있는 레코드들은 Update 레코드라 한다.

[그림 8] 트랜잭션 작업 구성
Checkpoint 레코드 외의 레코드들은 자신의 이전 작업 레코드의 LSN 값을 가지고 있다. 따라서 파일 시스템 복구 시, 운영체제는 트랜잭션 작업을 구성하는 레코드들을 역추적하면서 각 레코드들의 Undo 데이터를 사용하여 복구한다.
작업 레코드는 레코드 헤더와 데이터 영역으로 구성된다. 레코드 헤더는 고정된 0x58 크기를 가지며 데이터 영역은 Redo와 Undo 데이터가 들어가기 때문에 크기가 가변적이다.
따라서 작업 레코드의 크기도 가변적이며 큰 레코드는 여러 개의 페이지를 사용하기도 한다. 그리고 하나의 작업 레코드가 끝나면 바로 이어서 다음 작업 레코드가 이어진다. 상세한 작업 레코드 헤더 구조는 [그림 9]와 같다.

[그림 9] 작업 레코드의 헤더 구조
각 필드의 대한 설명은 [표 3]과 같다.
|
필드명
|
내용
|
|
This LSN
|
현재 작업 레코드의 LSN
|
|
Previous LSN
|
이전 작업 레코드의 LSN
|
|
Client Undo LSN
|
복구 시 다음 Undo 작업을 가지고 있는 레코드의 LSN
|
|
Client Data Length
|
레코드의 크기
Redo Op 시작 위치부터 이 값을 더하면 레코드 끝을 구할 수 있음 |
|
Record Type
|
0x02(Check Point Record)
0x01(그 외 Record) |
|
Flags
|
0x01(현재 레코드가 페이지를 넘어감)
0x00(현재 레코드가 페이지를 넘어가지 않음) |
|
Redo Op
|
Redo 연산 코드
|
|
Undo Op
|
Undo 연산 코드
|
|
Redo Offset
|
Redo 데이터 시작 Offset(Redo Op 위치부터)
|
|
Redo Length
|
Redo 데이터 크기
|
|
Undo Offset
|
Undo 데이터 시작 Offset(Redo Op 위치부터)
|
|
Undo Length
|
Undo 데이터 크기
|
|
LCNs to Follows
|
0x01(이어지는 레코드가 있음)
0x00(이어지는 레코드가 없음) |
|
Record Offset
|
MFT 레코드에 의한 작업이면, Redo/Undo 데이터가 적용되는 속성의 MFT 레코드 내 Offset
|
|
MFT 레코드에 대한 작업이 아니면, 값은 0x00
|
|
|
Attr Offset
|
MFT 레코드에 대한 작업이면, Redo/Undo 데이터가 적용되는 속성 내 Offset
|
|
MFT 레코드에 대한 작업이 아니면, Redo/Undo 데이터가 적용되는 클러스터 내Offset
|
|
|
Target LCN
|
Redo/Undo 데이터가 적용되는 디스크상의 LCN(Logical Cluster Number)
|
[표 3] 작업 레코드 헤더의 필드 내용
Redo Op 필드와 Undo Op 필드는 실제 레코드가 어떠한 작업을 수행하였는지에 대한 정보를 가진다. [표 4]는 각 Redo Op와 Undo Op가 가지는 연산코드의 의미이다.
|
연산 코드
|
작업 내용
|
|
0x00
|
Noop
|
|
0x01
|
CompensationLogRecord
|
|
0x02
|
InitializeFileRecordSegment
|
|
0x03
|
DeallocateFileRecordSegment
|
|
0x04
|
WriteEndofFileRecordSegment
|
|
0x05
|
CreateAttribute
|
|
0x06
|
DeleteAttribute
|
|
0x07
|
UpdateResidentValue
|
|
0x08
|
UpdataeNonResidentValue
|
|
0x09
|
UpdateMappingPairs
|
|
0x0A
|
DeleteDirtyClusters
|
|
0x0B
|
SetNewAttributeSizes
|
|
0x0C
|
AddIndexEntryRoot
|
|
0x0D
|
SetIndexEntryVenAllocation
|
|
0x0F
|
UpdateFileNameRoot
|
|
0x12
|
UpdateFileNameAllocation
|
|
0x13
|
SetBitsInNonresidentBitMap
|
|
0x14
|
UpdateFileNameAllocation
|
|
0x15
|
SetBitsInNonresidentBitMap
|
|
0x16
|
ClearBitsInNonresidentBitMap
|
|
0x19
|
Prepare Transaction
|
|
0x1A
|
CommitTransaction
|
|
0x1B
|
ForgetTransaction
|
|
0x1C
|
OpenNonresidentAttribute
|
|
0x1F
|
DirtyPageTableDump
|
|
0x20
|
TransactionTableDump
|
|
0x21
|
UpdateRecordDataRoot
|
[표 4] Redo/Undo 연산 코드
지금까지 NTFS $LogFile 구조에 대해 설명했다. 이제부터는 위 내용을 바탕으로 NTFS 파일 시스템 이벤트에 대해 알아보도록 한다.
파일 생성 이벤트 분석
NTFS에서 파일이 생성되면, $LogFile에는 [그림 10]과 같이 6개의 작업 레코드들이 순서대로 만들어진다. 6개의 레코드들 중 중요한 작업 레코드는 ’Add Index Entry Allocation’ Redo 작업과 ’Initialize File Record Segment’ Redo 작업을 하는 레코드다.
각 레코드들이 하는 작업은 부모 디렉터리의 MFT 엔트리 $INDEX 속성에 인덱스 레코드를 추가하는 것과 MFT 엔트리를 새롭게 할당하는 작업인 것을 알 수 있다.

[그림 10] 파일 생성 이벤트의 작업 순서
따라서 위 두 레코드들이 연속적으로 존재한다면 새로운 파일 생성 이벤트라고 판단할 수 있다. 특히 ’Initialize File Record Segment’ Redo 작업을 하는 레코드의 Redo 데이터는 MFT 엔트리의 데이터와 동일하므로 [그림 11]과 같이 생성된 파일명과 시간 정보를 획득할 수 있다. 시간 정보는 FILETIME 형식을 사용한다.

[그림 11] 생성된 파일명과 시간 정보 획득
파일 삭제 이벤트 분석
파일이 삭제되면, [그림 12]와 같이 5개의 작업 레코드들이 순서대로 생성된다. 이 5개의 레코드들 중에서 ’Delete Index Entry Allocation’ Redo 작업과 ’Deallocation File Record Segment’ Redo 작업을 하는 레코드들을 통해 삭제 이벤트를 판별할 수 있다. 즉 부모 디렉터리의 MFT 엔트리 $INDEX 속성에서 해당 파일의 인덱스 엔트리를 삭제하는 작업과 MFT 레코드를 비활성화하는 작업을 통해서 해당 파일이나 디렉터리의 삭제 작업을 알 수 있다.

[그림 12] 파일 삭제 이벤트의 작업 순서
또한 [그림 13]과 같이 ’Delete Index Entry Allocation’ Redo 작업을 하는 레코드의 Undo 데이터를 통해 삭제된 파일이나 디렉터리의 이름을 알 수 있다.

[그림 13] 삭제된 파일명 정보 획득
파일 데이터 작성 이벤트 분석
파일 데이터 작성 이벤트는 Resident 타입과 Non-Resident 타입을 구분해야 한다. Resident 타입은 MFT 엔트리 안에 데이터가 쓰여지기 때문에 ’Update Resident Value’ Redo 작업이어야 하고, 일반적으로 $DATA 속성의 0x18 오프셋 위치에 데이터가 작성되므로 [그림 14]와 같이 레코드 헤더의 ’Attr Offset’의 값이 0x18인 것도 추가로 확인해야 한다. 위 두 가지 조건을 만족하면 해당 레코드를 Resident 타입의 파일 데이터 작성 이벤트로 구분할 수 있다.

[그림 14] Resident 파일 데이터 작성 이벤트의 작업
또한 해당 레코드의 Redo 데이터를 통해 [그림 15]와 같이 작성된 파일 데이터의 내용을 확인할 수 있다.

[그림 15] 작성된 Resident 파일 데이터 획득
Non-Resident 타입은 파일 데이터가 클러스터 런 구조를 사용해서 저장되므로 ’Update Mapping Pairs’ Redo 작업이어야 하고 $DATA 속성의 0x40 위치부터 클러스터 런 데이터가 저장되므로 [그림 16]과 같이 레코드 헤더의 ’Attr Offset’ 값이 0x40인지 확인해야 한다. 위 두 가지 조건이 만족되면 해당 레코드를 Non-Resident 타입의 파일 데이터 작성 이벤트로 구분할 수 있다.
[그림 16] Non-Resident 파일 데이터 작성 이벤트의 작업
추가적으로 Redo 데이터에 있는 클러스터 런을 해석하면 [그림 17]과 같이 디스크상에서 해당 파일의 데이터가 존재하는 클러스터 주소와 할당된 클러스터 수를 알 수 있다. 아래 예에서는 해당 파일의 데이터가 클러스터 26부터 시작하여 2개의 클러스터를 할당하여 사용하고 있음을 알 수 있다.

[그림 17] 작성된 Non-Resident 파일의 데이터 위치 정보 획득
파일명 변경 이벤트 분석
파일명 변경 이벤트는 MFT 엔트리 내의 $FILE_NAME 속성을 삭제하고 다시 생성하는 방식으로 이루어진다. 따라서 [그림 18]과 같이 ’Delete Attribute’ Redo 작업과 ’Create Attribute’ Redo 작업이 연속적으로 일어나고 각 레코드의 Record Offset 필드의 값이 0x98, Attr Offset 필드의 값이 0x00이면 파일명 변경 이벤트라고 구분할 수 있다.

[그림 18] 파일명 변경 이벤트의 작업 순서
그리고 [그림 19]와 같이 각 레코드의 Redo 데이터를 통해 변경 전의 파일명과 변경 후의 파일명을 확인할 수 있다.

[그림 19] 변경 전/후의 파일명 정보 획득
지금까지 $LogFile에서 획득할 수 있는 파일 시스템 이벤트에 대해 알아보았다. 그렇다면 이러한 이벤트 정보를 바탕으로 디지털 포렌식 분석가가 얻을 수 있는 이점은 무엇일까?
$LogFile 분석의 활용
$LogFile 분석을 통해 얻을 수 있는 이점은 다음과 같다.
1) 순차적인 파일•디렉터리 생성, 삭제, 데이터 작성, 이름 변경 이벤트를 획득하여 파일 시스템 이벤트에 대한 타임라인 작성이 가능하다. 이를 통해 사용자의 행위 또는 악성코드의 행위를 추적할 수 있다.
2) 삭제된 파일을 추적하는 데 유용하게 사용될 수 있다. 일반적으로 삭제된 파일의 비활성화된 MFT 엔트리는 다른 파일의 MFT 엔트리로 덮어쓸 수 있는데, 이 경우 MFT 분석을 통해서는 삭제된 파일의 흔적을 찾을 수 없다. 하지만 $LogFile을 분석하면 삭제된 파일의 파일명과 파일 데이터 혹은 데이터 위치를 얻을 수 있다.
3) 프리 패치 파일과 링크 파일 생성 이벤트를 통해 프로그램 실행, 문서 파일 열람 행위를 추적할 수 있다.
일반적으로 지금까지의 디지털 포렌식 조사 과정에서 NTFS 분석은 MFT 분석을 통해서만 진행됐다. 하지만 $LogFile 분석을 추가로 활용한다면 MFT에서 얻지 못한 정보를 획득해 사고를 분석함으로써 더욱 정확한 타임 라인 작성이 가능하다. 이는 디지털 포렌식 조사 과정에서 공격자의 행위나 악성코드 행위를 분석하는 데에 큰 도움이 될 것이다.
출처 : 안랩
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| » | NTFS와 $LogFile | proin | 2020.03.27 | 1 |